
Инфанрикс Гекса особенно важна для младенцев и маленьких детей, у которых еще не сформирована

Принимая активные шаги для укрепления иммунной системы, вы можете значительно уменьшить риск заражения различными

Решение кроссвордов — это увлекательное занятие, которое может стать еще интереснее и проще, если

Толстой умер 20 ноября 1910 года на железнодорожной станции Астапово после бегства из дома

К люксовой и премиальной парфюмерии относятся широко известные дорогие ароматы, которые представлены в фирменных

В эпоху массового производства, персонализированные подарки и сувениры становятся все более ценными, и гравировка

Точность в медицинском переводе жизненно важна. Ошибка в переводе может привести к неправильной диагностике,

Выбор женского зонта не ограничивается только его внешним видом. Важно обращать внимание на качество
Вакцинация от бешенства (возбудитель — Rabies lyssavirus) является обязательной в виду особой опасности заболевания

Поход за украшениями в торгово-развлекательный центр (ТРЦ) может превратиться в настоящее приключение.

Весна 2024 года обещает быть яркой и новаторской в мире моды. Последние тенденции в

Военные тематические мероприятия представляют собой уникальный способ ознакомления с историей через погружение в атмосферу


Традиционная свадьба чаще всего включает в себя классические элементы: официальную церемонию бракосочетания, обмен клятвами,

Выбор гранитора зависит от нескольких факторов, включая объем напитков, который планируется продавать, и доступное

Пароконвектомат и духовой шкаф являются ключевым оборудованием в современной кулинарии, но многие задаются вопросом

При выборе аттракционов и реквизита для вашего праздника важно учитывать возраст участников, тематику мероприятия

Наркологическая клиника играет ключевую роль в процессе лечения и реабилитации людей, страдающих от наркотической


Онлайн-школы и курсы для будущих мам предлагают удобный и доступный способ получения важной и

Школьные экскурсии играют важную роль в образовательном процессе, предоставляя учащимся уникальные возможности для обучения
Это современный и эффективный метод удаления волос, обладающий высокой эффективностью, безопасностью и комфортом для

Сумки являются неотъемлемой частью повседневной жизни большинства людей. Они сочетают в себе практичность и

Ключевые инструменты в арсенале парикмахера включают в себя ножницы различных типов, расчески, щетки, машинки

Когда в доме есть дети, бардак становится частью повседневной рутины. Разбросанные игрушки, разорванные книги,

Новый год – время волшебства и подарков, особенно для детей. Детские новогодние подарки сладкие
Важным аспектом ухода за своим здоровьем является регулярное посещение врачей-специалистов, включая гинеколога. В данной
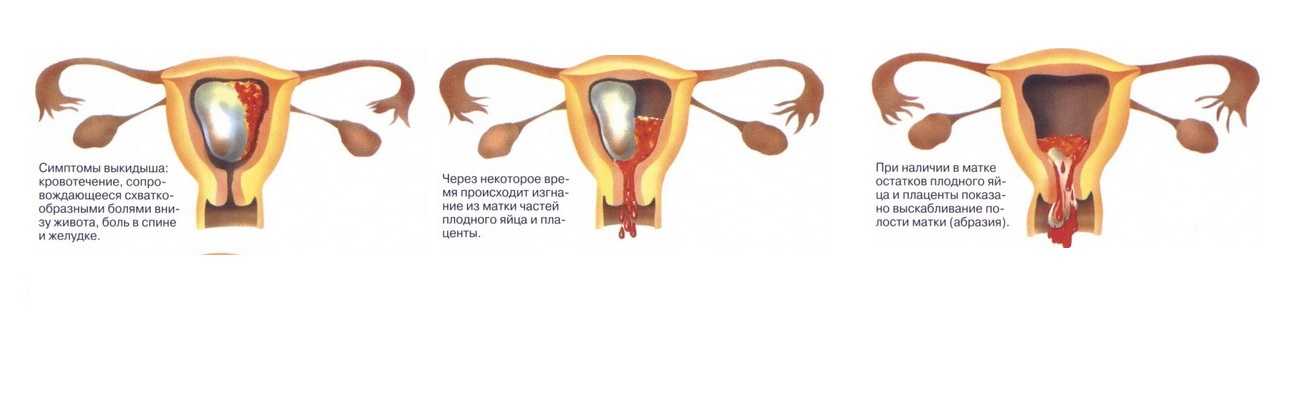
Раньше об этом старались не говорить, но сейчас знаменитости без стеснения откровенничают на тему собственной

Сегодня расскажем о девочках, которые невероятно похожи на своих бабушек – знаменитых и не

Браки с большой разницей в возрасте среди знаменитостей